![[轮子系列]Google Guava之CharMatcher源码分析](/content/images/size/w450h450/2018/07/004.00.png)
最近遇到了一些字符匹配的需求,进而仔细地看了CharMatcher的源码,发现还是有点东西值得回味,例如它为我们提供了如何在多种字符类型场景下提高灵活性从而满足不同匹配需求的优秀示范。下面就对CharMatcher类的结构,设计模式,以及几个算法做一些粗浅的分析。
一、关于源码中的彩蛋
CharMatcher类中,开头部分有一张宠物小精灵“小火龙”的字符画,就像本文的封面图一样,一开始不解为何要放一只“小火龙”在这里,后来看到其英文名Charmander才明白过来。好吧,谐音梗……略冷。
二、类的结构和关系
下图是CharMatcher的类关系图,图中蓝色的是abstract类,红色的是final类
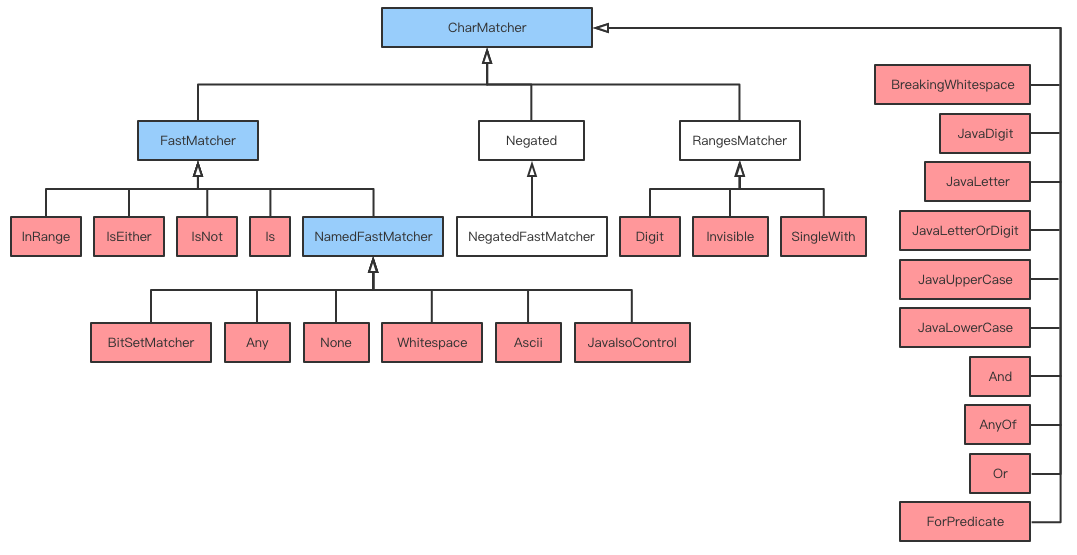
首先CharMatcher修饰为abstract,其中只有一个abstract方法matches,即判断给定字符是否匹配,以及一些其他的常用操作(它们的功能从方法名可以得知,这里就不一一介绍了,下文会选其中的一些做分析),此外还有三个用于组合的方法:negate、or、and。
public abstract boolean matches(char c);
public int indexIn(CharSequence sequence) // 查找匹配字符首次出现的索引位置
public int countIn(CharSequence sequence) // 对匹配的字符计数
public String retainFrom(CharSequence sequence) // 抽取匹配的字符
public CharMatcher negate() // 取反
public CharMatcher and(CharMatcher other) // 与
public CharMatcher or(CharMatcher other) // 或
...
如上图所示,CharMatcher类有很多的子类,一部分是直接继承于父类,一部分是继承于FastMatcher,另外还有继承于Negated和RangeMatcher。子类通过实现matches方法或重写其他父类的方法,从而提供了各种不同的具体操作,如Is(判断是否为某一个字符),Digit(判断是否为数字字符),Ascii(判断是否为ASCII字符)等。
再来说说其中一个比较重要的子类——FastMatcher,它和CharMatcher的主要区别在于,FastMatcher取消了父类中相对复杂的precomputed方法,其注释写道,这个方法可以得到一个处理速度更快的实例,但是执行该方法本身需要花费一定时间,所以只有在需要频繁调用的情况下,这样做才比较划算。
至于这个方法的奥秘在于,它使用BitSet作为存储字符的数据结构,然后遍历所有的字符(Character.MIN_VALUE~Character.MAX_VALUE),根据matches方法放入这个BitSet中,最后根据这个BitSet中1的数量生成其他类型的CharMatcher实例,包括None,Is,IsEither,SmallCharMatcher(一个单独的子类)以及BitSetMatcher,这样就避免了频繁调用过程中,(特别是复杂组合的情况)执行不必要实例化操作,而是直接归约到某一个类的实例上。
而上述那5个类正是继承于FasterMatcher(或NamedFasterMatcher)。
三、设计模式
上一节说到CharMatcher提供很多子类,为了较好地管理和使用这些类,CharMatcher对外提供了基于内部类的静态工厂方法或者单例模式来获得某个实例,举例来说:
- 静态工厂方法
public static CharMatcher is(final char match) {
return new Is(match);
}
private static final class Is extends FastMatcher {
private final char match;
Is(char match) {
this.match = match;
}
...
}
使用静态工厂方法的好处,这点在《Effective Java》一书中有详细的介绍
- 单例模式
public static CharMatcher ascii() {
return Ascii.INSTANCE;
}
private static final class Ascii extends NamedFastMatcher {
static final Ascii INSTANCE = new Ascii();
Ascii() {
super("CharMatcher.ascii()");
}
...
}
这样我们就可以很方便地获得一个实例,并对相应的字符类型做处理,比如抽取字符串中所有的数字
CharMatcher.inRange('0', '9').retainFrom("abc12d34ef");
// 当然也可以用Digit类,不过最近的版本已经被标记为Deprecated
// 区别在于Digit类处理了字符0到9的各种unicode码,不过大多数情况还是处理ASCII数字,所以建议使用inRange
CharMatcher.digit().retainFrom("abc12d34ef");
// 1234
当然也可以通过negate/or/and产生一些复杂的组合:
CharMatcher.inRange('0','9').or(CharMatcher.is('d')).retainFrom("abc12d34ef");
// 12d34
另外还有一个ForPredicate的子类,它接收Predicate对象作为参数,然后用Predicate的apply方法来实现matches方法,这样就用lamda表达式创建一些实例了,例如:
CharMatcher.inRange('0', '9').or(CharMatcher.is('d'))
.or(CharMatcher.forPredicate(c -> c <= 'b' || c > 'e')).retainFrom("abc12d34ef");
// ab12d34f
四、算法分析
- collapseFrom方法,如代码注释所示,把一个字符串中匹配到的(连续)部分替换为给定的字符,
//CharMatcher.anyOf("eko").collapseFrom("bookkeeper", '-') returns "b-p-r"
public String collapseFrom(CharSequence sequence, char replacement) {
// This implementation avoids unnecessary allocation.
int len = sequence.length();
for (int i = 0; i < len; i++) {
char c = sequence.charAt(i);
if (matches(c)) {
if (c == replacement && (i == len - 1 || !matches(sequence.charAt(i + 1)))) {
// a no-op replacement
i++;
} else {
StringBuilder builder = new StringBuilder(len).append(sequence, 0, i).append(replacement);
return finishCollapseFrom(sequence, i + 1, len, replacement, builder, true);
}
}
}
// no replacement needed
return sequence.toString();
}
private String finishCollapseFrom(
CharSequence sequence,
int start,
int end,
char replacement,
StringBuilder builder,
boolean inMatchingGroup) {
for (int i = start; i < end; i++) {
char c = sequence.charAt(i);
if (matches(c)) {
if (!inMatchingGroup) {
builder.append(replacement);
inMatchingGroup = true;
}
} else {
builder.append(c);
inMatchingGroup = false;
}
}
return builder.toString();
}
事实上,CharMatcher里面的算法基本上都和这个差不多程度。
正如注释部分所述,这个算法没有分配不必要的空间。遍历过程中当发现当前字符满足匹配条件,这时再做一次判断,如果当前字符本身就是所需要替换的字符replacement,那么这种情况是不需要进行替换操作(感觉可以直接用一个if(c != replacement)换掉else,并不需要i++的操作),否则将i之前的字符拼上replacement形成一个“半成品”传入finishCollapseFrom,在该方法中利用了一个布尔值inMatchingGroup来控制是否需要拼接replacement,当发现满足匹配条件时,再检查inMatchingGroup是否为false,它表示上一轮拼接的不是replacement,以保证返回的结果中不会出现两个以上连续的replacement。
- Whitespace.matches 即判断该字符是否为空白字符,包括空格,换行等
static final class Whitespace extends NamedFastMatcher {
static final String TABLE =
"\u2002\u3000\r\u0085\u200A\u2005\u2000\u3000"
+ "\u2029\u000B\u3000\u2008\u2003\u205F\u3000\u1680"
+ "\u0009\u0020\u2006\u2001\u202F\u00A0\u000C\u2009"
+ "\u3000\u2004\u3000\u3000\u2028\n\u2007\u3000";
static final int MULTIPLIER = 1682554634;
static final int SHIFT = Integer.numberOfLeadingZeros(TABLE.length() - 1);
static final Whitespace INSTANCE = new Whitespace();
@Override
public boolean matches(char c) {
return TABLE.charAt((MULTIPLIER * c) >>> SHIFT) == c;
}
}
这个算法本身很简单,即TABLE字符串中是否存在同样的字符c,巧妙的是它的定位方式。
先说明Integer.numberOfLeadingZeros这个方法返回的是该int变量二进制开头部分连续的零的个数。TABLE的长度为32,故SHIFT的值为27,也就是说,通过字符c和某一个乘子的乘积(超出int范围之后取低32位)向右移动27位得到的数值,即为TABLE的下标索引,例如字符'\u2002'其值为8194,它和1682554634的乘积再右移27位得到0,而TABLE第0个字符就是'\u2002',则判定相等,字符'\u3000'的值为12288,应用相同算法得到26,TABLE第26个字符也是'\u3000',同样判定相等。由此可以看出,1682554634这个魔数和TABLE是刻意设计成这样的。但是源码中没有解释如何生成,在GitHub上倒是也有人这么问过,Guava owner回复说道:他们确实有一个生成器,但是由于一些依赖的原因,并没有开源出来。其实如果不考虑性能,我们可以用最简单的暴力法生成乘子和TABLE,代码如下:
@Test
public void test() {
// 去掉table中重复的字符
String WHITE = "\u2002\r\u0085\u200A\u2005\u2000"
+ "\u2029\u000B\u2008\u2003\u205F\u1680"
+ "\u0009\u0020\u2006\u2001\u202F\u00A0\u000C\u2009"
+ "\u2004\u2028\n\u2007\u3000";
char[] chars = WHITE.toCharArray();
char filler = chars[chars.length - 1];
char[] table = new char[32];
int shift = Integer.numberOfLeadingZeros(WHITE.length());
for (int i = 0; i <= Integer.MAX_VALUE; i++) {
Arrays.fill(table, filler);//先用最后一个字符填充整个table
boolean conflict = false;
for (char c : chars) {
int index = (i * c) >>> shift;
//如果当前字符为填充字符,则覆盖填充字符,否则跳过
if (table[index] != filler) {
conflict = true;
continue;
}
table[index] = c;
}
if (conflict)
continue;
System.out.println("MULTIPLIER: " + i);
System.out.println("TABLE:" + new String(table));
}
}
上面可以得到多种MULTIPLIER和TABLE的结果。当然,反推过程比较简单粗暴,一定有更优雅更高效的实现方式。不过这里想要表达的是,它本身是一个简单的查找算法,通常的复杂度为O(logn),这里巧妙通过映射函数,将字符映射为字符串下标索引,使得时间复杂度为O(1),不得不佩服Guava开发者们追求极致的精神。
- removeFrom方法,即在给定字符串中,删除其匹配的部分
// CharMatcher.is('a').removeFrom("bazaar") returns "bzr"
public String removeFrom(CharSequence sequence) {
String string = sequence.toString();
int pos = indexIn(string);
if (pos == -1) {
return string;
}
char[] chars = string.toCharArray();
int spread = 1;
// This unusual loop comes from extensive benchmarking
OUT:
while (true) {
pos++;
while (true) {
if (pos == chars.length) {
break OUT;
}
if (matches(chars[pos])) {
break;
}
chars[pos - spread] = chars[pos];
pos++;
}
spread++;
}
return new String(chars, 0, pos - spread);
}
比较诡异的是,它使用了两层while循环,以及break [lable]的语法(这种用法并不多见,可以理解为goto语句的改良形式,可以方便地跳出多层循环),不过在内层循环时同样也做了pos++的操作,本质上还是O(n)的时间复杂度,算法思想是char数组的位移操作,每次匹配到一个字符时,spread就自增,其他情况则每个数组元素向前移动,具体来说,spread的作用相当于对匹配到的字符进行计数,匹配到1个元素,pos指向的元素及其之后的元素向前移动1步以覆盖掉上一轮命中的字符,匹配到2个元素,pos执行的元素及其之后的元素向前移动2步,以覆盖上一次移动留下的空位和上一轮命中的字符,依次类推。最终利用String的构造函数(第二个参数是offset,即初始的偏移位置,第三个参数count,即所需长度)返回正确的字符串。
做个对比,我们以Apache commons lang3中的StringUtils作为比较对象,其对应的实现基于Matcher(java.util.regex)的replaceAll方法,亦即将匹配的字符替换为空字符串,整个遍历的过程中重复调用了find()方法,该方法查找当前字符串中匹配的字符,它每次都需要从头进行搜索,因此时间复杂度为O(n^2),这样就比较费时了。
五、其他
在CharMatcher罗列多种字符的不同Unicode码,如果你在其他的工作场景下需要用的这些unicode,可以参考一下CharMatcher。
- 数字字符
private static final String ZEROES =
"0\u0660\u06f0\u07c0\u0966\u09e6\u0a66\u0ae6\u0b66\u0be6\u0c66\u0ce6\u0d66\u0de6"
+ "\u0e50\u0ed0\u0f20\u1040\u1090\u17e0\u1810\u1946\u19d0\u1a80\u1a90\u1b50\u1bb0"
+ "\u1c40\u1c50\ua620\ua8d0\ua900\ua9d0\ua9f0\uaa50\uabf0\uff10";
如果要获得其他数字的unicode,就直接对应加上对应的数值
- 空白字符
static final String TABLE =
"\u2002\u3000\r\u0085\u200A\u2005\u2000\u3000"
+ "\u2029\u000B\u3000\u2008\u2003\u205F\u3000\u1680"
+ "\u0009\u0020\u2006\u2001\u202F\u00A0\u000C\u2009"
+ "\u3000\u2004\u3000\u3000\u2028\n\u2007\u3000";
- 不可见字符
private static final String RANGE_STARTS =
"\u0000\u007f\u00ad\u0600\u061c\u06dd\u070f\u08e2\u1680\u180e\u2000\u2028\u205f\u2066"
+ "\u3000\ud800\ufeff\ufff9";
private static final String RANGE_ENDS = // inclusive ends
"\u0020\u00a0\u00ad\u0605\u061c\u06dd\u070f\u08e2\u1680\u180e\u200f\u202f\u2064\u206f"
+ "\u3000\uf8ff\ufeff\ufffb";
- 单字节长度字符
"\u0000\u05be\u05d0\u05f3\u0600\u0750\u0e00\u1e00\u2100\ufb50\ufe70\uff61"
"\u04f9\u05be\u05ea\u05f4\u06ff\u077f\u0e7f\u20af\u213a\ufdff\ufeff\uffdc"
中文字符就是双字节长度
