
零、铺垫
在介绍B树之前,先来看另一棵神奇的树——二叉排序树(Binary Sort Tree),首先它是一棵树,“二叉”这个描述已经很明显了,就是树上的一根树枝开两个叉,于是递归下来就是二叉树了(下图所示),而这棵树上的节点是已经排好序的,具体的排序规则如下:
- 若左子树不空,则左子树上所有节点的值均小于它的根节点的值
- 若右子树不空,则右字数上所有节点的值均大于它的根节点的值
- 它的左、右子树也分别为二叉排序数(递归定义)
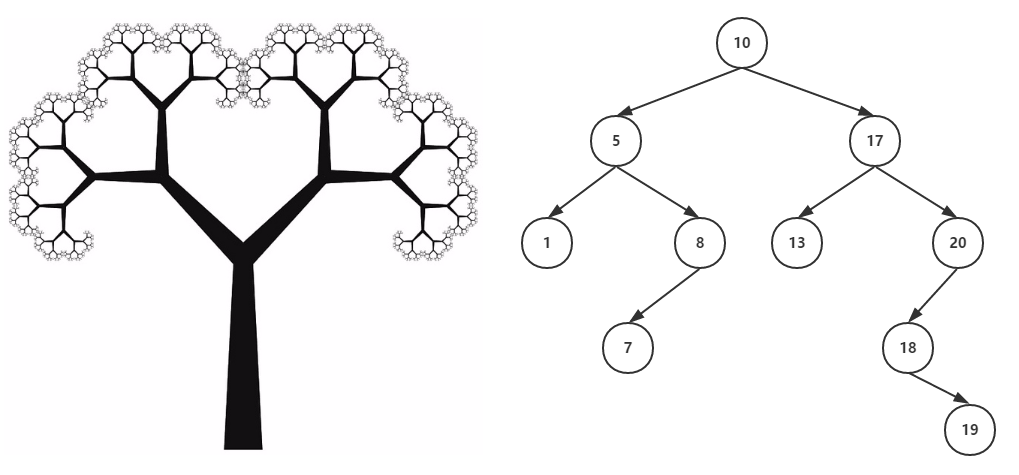
从图中可以看出,二叉排序树组织数据时,用于查找是比较方便的,因为每次经过一次节点时,最多可以减少一半的可能,不过极端情况会出现所有节点都位于同一侧,直观上看就是一条直线,那么这种查询的效率就比较低了,因此需要对二叉树左右子树的高度进行平衡化处理,于是就有了平衡二叉树(Balenced Binary Tree),所谓“平衡”,说的是这棵树的各个分支的高度是均匀的,它的左子树和右子树的高度之差绝对值小于1,这样就不会出现一条支路特别长的情况。于是,在这样的平衡树中进行查找时,总共比较节点的次数不超过树的高度,这就确保了查询的效率(时间复杂度为O(logn))
一、B树的起源
B树,最早是由德国计算机科学家Rudolf Bayer等人于1972年在论文 《Organization and Maintenance of Large Ordered Indexes》提出的,不过我去看了看原文,发现作者也没有解释为什么就叫B-trees了,所以把B树的B,简单地解释为Balanced或者Binary都不是特别严谨,也许作者就是取其名字Bayer的首字母命名的也说不定啊……
二、B树长啥样
还是直接看图比较清楚,图中所示,B树事实上是一种平衡的多叉查找树,也就是说最多可以开m个叉(m>=2),我们称之为m阶b树,为了体现本博客的良心之处,不同于其他地方都能看到2阶B树,这里特意画了一棵5阶B树 。
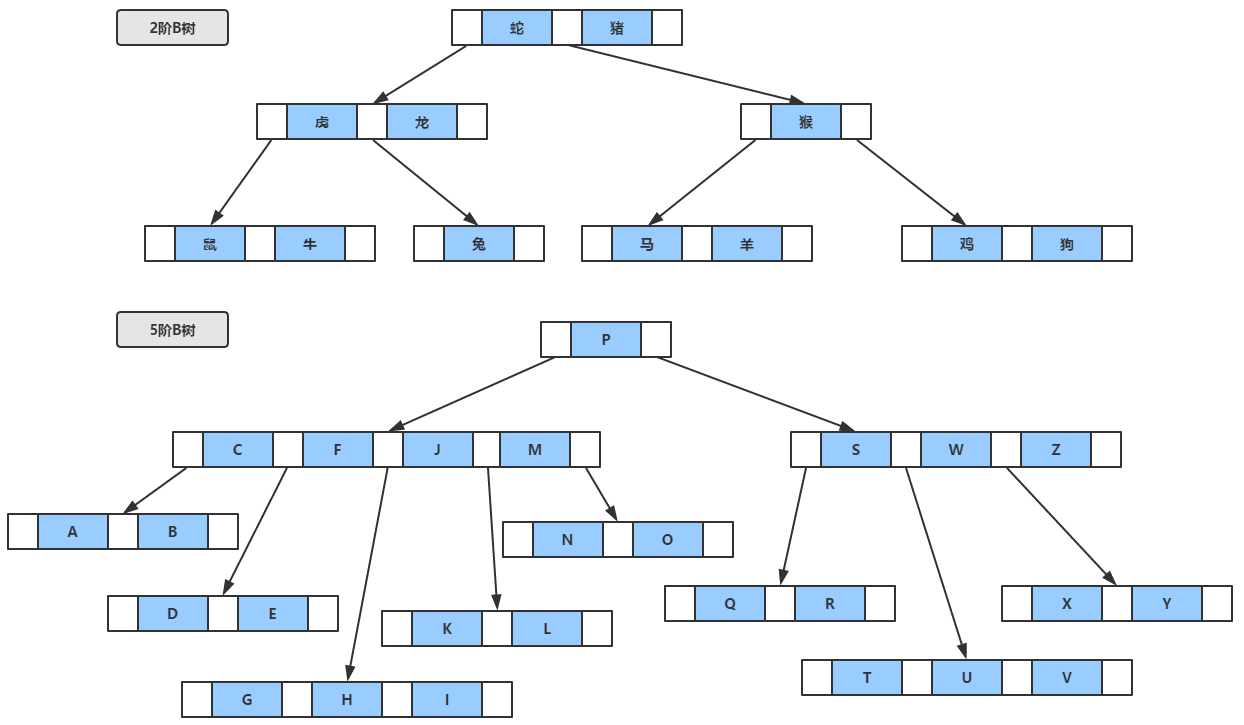
总的来说,m阶B树满足以下条件:
- 每个节点至多可以拥有m棵子树
- 根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
- 非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,图中5阶B树,每个节点至少有3个子树,也就是至少有3个叉)
- 非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针
- 从根到叶子的每一条路径都有相同的长度,也就是说,叶子节在相同的层,并且这些节点不带信息,实际上这些节点就表示找不到指定的值,也就是指向这些节点的指针为空
B树的查询过程和二叉排序树比较类似,从根节点依次比较每个结点,因为每个节点中的关键字和左右子树都是有序的,所以只要比较节点中的关键字,或者沿着指针就能很快地找到指定的关键字,如果查找失败,则会返回叶子节点,即空指针。
例如查询图中字母表中的K
- 从根节点P开始,K的位置在P之前,进入左侧指针
- 左子树中,依次比较C、F、J、M,发现K在J和M之间
- 沿着J和M之间的指针,继续访问子树,并依次进行比较,发现第一个关键字K即为指定查找的值
三、Plus版——B+树
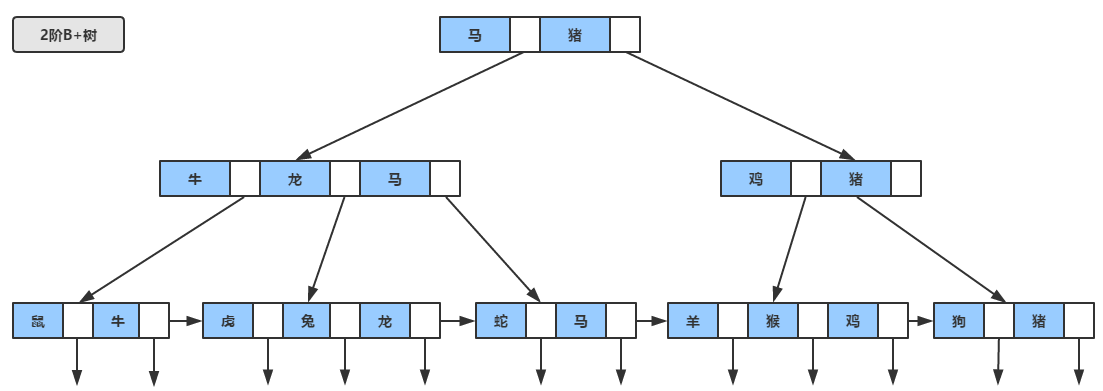
作为B树的加强版,B+树与B树的差异在于
- 有n棵子树的节点含有n个关键字(也有认为是n-1个关键字)
- 所有的叶子节点包含了全部的关键字,及指向含这些关键字记录的指针,且叶子节点本身根据关键字自小而大顺序连接
- 非叶子节点可以看成索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
四、MySQL是如何使用B树的
说明:事实上,在MySQL数据库中,诸多存储引擎使用的是B+树,即便其名字看上去是BTREE。
4.1 innodb的索引机制
先以innodb存储引擎为例,说明innodb引擎是如何利用B+树建立索引的
首先创建一张表:zodiac,并插入一些数据
CREATE TABLE `zodiac` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(4) NOT NULL,
PRIMARY KEY (`id`),
KEY `index_name` (`name`)
);
insert zodiac(id,name) values(1,'鼠');
insert zodiac(id,name) values(2,'牛');
insert zodiac(id,name) values(3,'虎');
insert zodiac(id,name) values(4,'兔');
insert zodiac(id,name) values(5,'龙');
insert zodiac(id,name) values(6,'蛇');
insert zodiac(id,name) values(7,'马');
insert zodiac(id,name) values(8,'羊');
insert zodiac(id,name) values(9,'猴');
insert zodiac(id,name) values(10,'鸡');
insert zodiac(id,name) values(11,'狗');
insert zodiac(id,name) values(12,'猪');
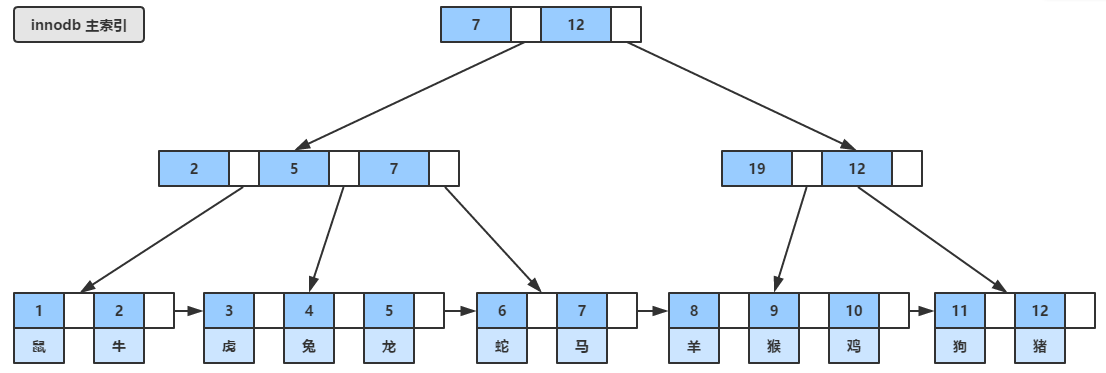
对于innodb来说,只有一个数据文件,这个数据文件本身就是用B+树形式组织,B+树每个节点的关键字就是表的主键,因此innode的数据文件本身就是主索引文件,如下图所示,主索引中的叶子页(leaf page)包含了数据记录,但非叶子节点只包含了主键,术语“聚簇”表示数据行和相邻的键值紧凑地存储在一起,因此这种索引被称为聚簇索引,或聚集索引。这种索引方式,可以提高数据访问的速度,因为索引和数据是保存在同一棵B树之中,从聚簇索引中获取数据通常比在非聚簇索引中要来得快。
所以可以说,innodb的数据文件是依靠主键组织起来的,这也就是为什么innodb引擎下创建的表,必须指定主键的原因,如果没有显式指定主键,innodb引擎仍然会对该表隐式地定义一个主键作为聚簇索引。
同样innodb的辅助索引,如下图所示,假设这些字符是按照生肖的顺序排列的(其实我也不知道具体怎么实现,不要在意这些细节,就是举个例子),其叶子节点中也包含了记录的主键,因此innodb引擎在查询辅助索引的时候会查询两次,首先通过辅助索引得到主键值,然后再查询主索引,略微有点啰嗦。。。
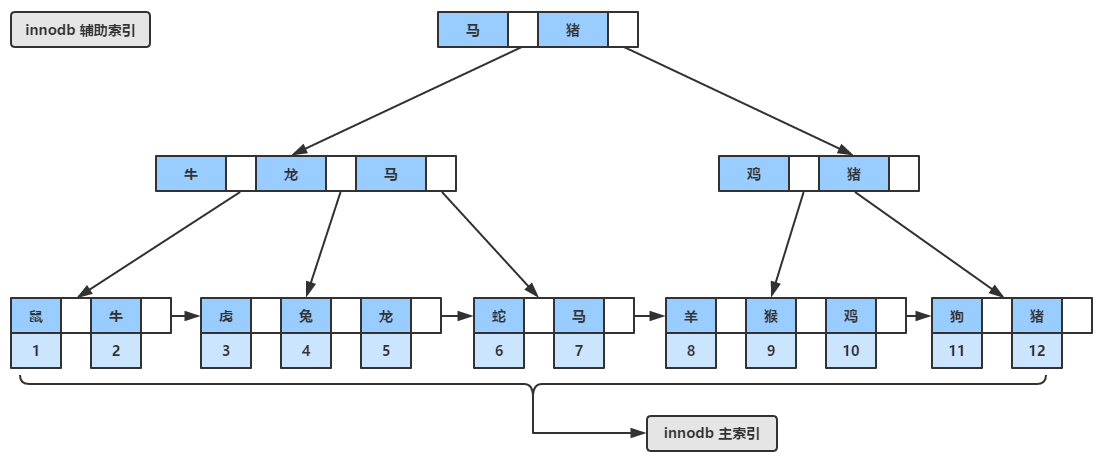
4.2 MyISAM的索引机制
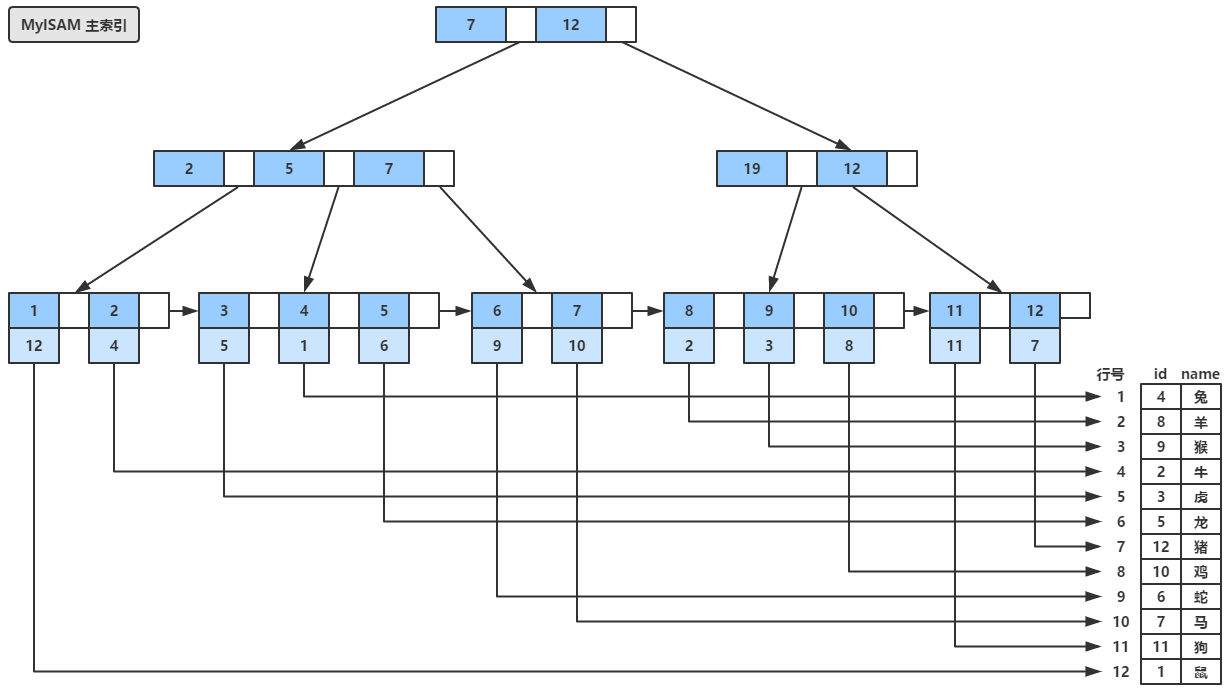
MyISAM引擎同样也使用B+树组织索引,如下图所示,假设我们的数据不是按照之前的顺序插入的,而是按照图中的是顺序插入表,可以看到MyISAM引擎下,B+树叶子节点中包含的是数据记录的地址(可以简单理解为“行号”),而MyISAM的辅助索引在结构上和主索引没有本质的区别,同样其叶子节点也包含了数据记录的地址,稍微不同的是辅助索引的关键字是允许重复
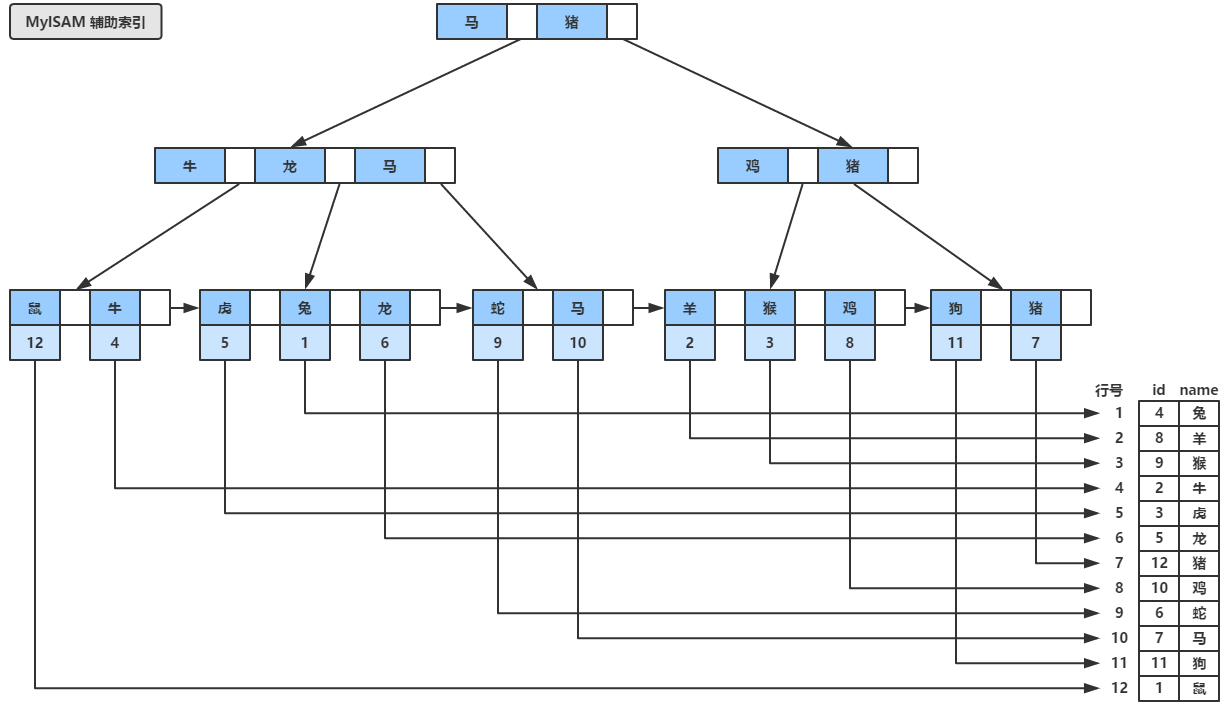
五、简单对比
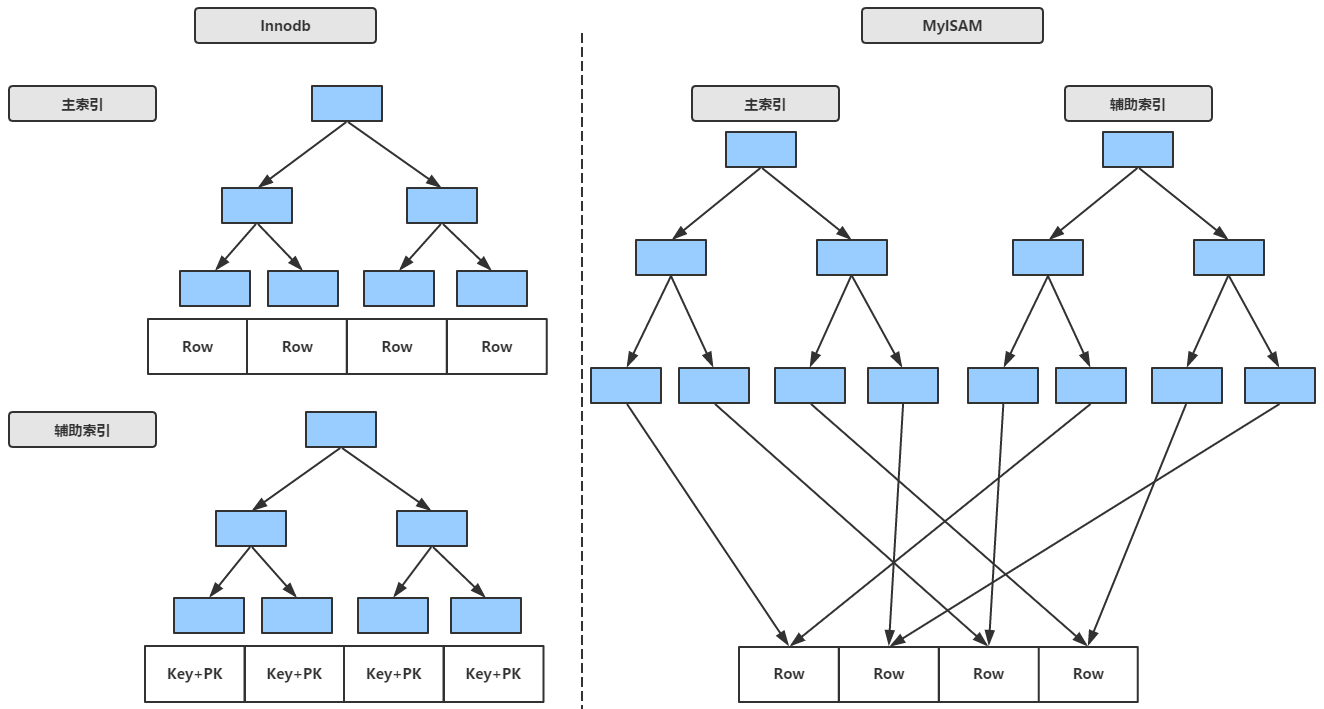
- Innodb辅助索引的叶子节点存储的不是地址,而是主键值,这样的策略减少了当出现行移动或者数据页分裂时辅助索引的维护工作,虽然使用主键值当作指针会让辅助索引占用更多空间,但好处是,Innodb在移动行时无需更新辅助索引中的主键值,而MyISAM需要调整其叶子节点中的地址
- innodb引擎下,数据记录是保存在B+树的叶子节点(大小相当于磁盘上的页)上,当插入新的数据时,如果主键的值是有序的,它会把每一条记录都存储在上一条记录的后面,但是如果主键使用的是无序的数值,例如UUID,这样在插入数据时Innodb无法简单地把新的数据插入到最后,而是需要为这条数据寻找合适的位置,这就额外增加了工作,这就是innodb引擎写入性能要略差于MyISAM的原因之一
Innodb和MyISAM索引的抽象图
六、参考文献
Bayer, R.; McCreight, E. (1972), “Organization and Maintenance of Large Ordered Indexes” (PDF), Acta Informatica, 1 (3): 173–189
http://www.minet.uni-jena.de/dbis/lehre/ws2005/dbs1/Bayer_hist.pdf
严蔚敏, 吴伟民. 数据结构: C 语言版[M]. 清华大学出版社有限公司, 2002.
http://cs.ecust.edu.cn/snwei/studypc/jsjdl/data/sjjgc.pdf
Schwartz B, Zaitsev P, Tkachenko V. High performance MySQL: Optimization, backups, and replication[M]. ” O’Reilly Media, Inc.”, 2012.
